Spark a Tez
18 Dec 2014Apache Tez jest wspaniałym, nowym narzędziem, pozwalającym na znaczne przyspieszenie wykonywania operacji w środowisku Hadoop. Jest stosunkowo mocno forsowany przez jednego z liderów rozwiązań big data, firmę Hortonworks. Tylko że jest też w znacznej mierze wtórny. Podobne koncepcje, w nieco ulepszonej wersji, zostały już wykorzystane w Apache Spark.
Hadoop, czyli jak to wszystko działa
Podstawą jest rozproszony system plików: HDFS. Dzięki niemu możliwe jest przechowywanie dużych plików na wielu maszynach jednocześnie, zapewniając przy tym ochronę przed utratą danych. Poszczególne pliki są replikowane – ich kopie znajdują się na oddzielnych serwerach, a awarie nawet kilku z nich nie doprowadzą do utraty danych.
Kolejną warstwą jest YARN, który służy do zarządzania tymi danymi. To dzięki YARN różne narzędzia – na przykład Hive, Pig, czy Spark – mogą odwoływać się do danych w HDFS i przeprowadzać obliczenia zgodnie z paradygmatem MapReduce.
Wspomniane narzędzia pozwalają przeprowadzać obliczenia w środowisku Hadoop znacznie łatwiej, niż za pośrednictwem samych zadań MapReduce, pisanych bezpośrednio w Javie. Hive dostarcza możliwości odpytywania danych tabelarycznych w HDFS za pośrednictwem języka bardzo zbliżonego do SQL. Pig pozwala na przetwarzanie danych z wykorzystaniem specjalnie stworzonego języka skryptowego – Pig Latin. Z wykorzystaniem Spark można natomiast przetwarzać dane zgodnie z kodem napisanym w języku Scala, Java lub Python.
We wszystkich tych narzędziach ostatecznie dochodzi do przetłumaczenia zadań przetwarzania danych na MapReduce i wywołanie ich za pośrednictwem YARN na HDFS. (Spark dodatkowo działa też na innego rodzaju klastrach, nie tylko w ramach Hadoopa).
Wydajność MapReduce
Klasyczne zadanie MapReduce składa się z następujących kroków:
- Wczytanie danych z HDFS.
map– przekształcanie danych na pary (klucz, wartość).- Grupowanie wartości względem klucza.
reduce– operacje powodujące agregację danych, np. sumowanie wszystkich wartości dla poszczególnych kluczy.- Zapisanie wyników na HDFS.
Wykonywanie obliczeń za pośrednictwem operacji MapReduce umożliwia niesamowitą skalowalność. Obliczenia mogą być wykonywane nawet na tysiącach maszyn jednocześnie. Wąskim gardłem jest jedynie konieczność synchronizowania danych przez sieć, a także konieczność wielokrotnego dostępu do systemu plików i wykonywania znacznej liczby operacji odczytu i zapisu.
W klasycznym zadaniu MapReduce dane są zawsze na początku wczytywane z HDFS, a na końcu zapisywane w HDFS. Problem pojawia się, kiedy należy wykonać sekwencję takich zadań, jak to ma miejsce w Pig, czy Hive.
Na pierwszym z dwóch schematów, pochodzących ze strony projektu Tez, pokazano, w jaki sposób wywoływane są klasycznie zadanie MapReduce w Hive i Pig.
Przed każdym krokiem map dane sa wczytywane z HDFS, a po każdym kroku reduce następuje zapis wyników na HDFS.
Wtedy też muszą zostać wykonane wszystkie dodatkowe operacje rozproszonego systemu plików, np. replikacja zapisanych danych.
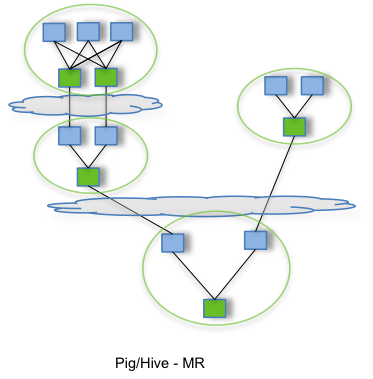
Drugi schemat pokazuje wywołanie tego samego skryptu Hive lub Pig z wykorzystaniem Tez, który eliminuje niepotrzebne operacje zapisu i odczytu.
To, co po reduce najpierw byłoby zapisywane w HDFS, a potem wczytywane przed map z kolejnego zadania MapReduce, dzięki Tez może być przekazane bezpośrednio.
Jeśli poszczególne operacje przebiegają bez zakłóceń, pośrednie wyniki nie są zapisywane w HDFS.
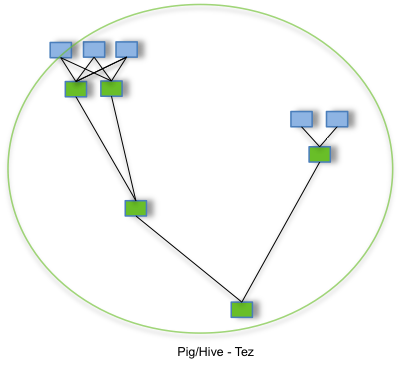
Do tego jest obecnie wykorzystywany i w tym celu powstał Tez: do eliminowania zbędnych operacji odczytu i zapisu na HDFS podczas wywoływania skryptów Hive i Pig. A Spark? Spark ma tego rodzaju optymalizację od dawna.
Trochę historii
Apache Tez powstał jako inicjatywa Hortonworks w celu optymalizacji wywoływania skryptów Hive i Pig. Została w nim wykorzystana koncepcja opisana w artykule Microsoftu z 2007 roku, Dryad: Distributed Data-Parallel Programs from Sequential Building Blocks. Autorzy zaproponowali w nim reprezentację procesów rozproszonego przetwarzania danych w postaci acyklicznego grafu skierowanego, gdzie krawędzie oznaczały operacje na danych. Poszczególne dane pośrednie miały być zachowywane w pamięci operacyjnej i usuwane z niej zaraz po tym, kiedy przestawały być potrzebne. Po kilku latach, w roku 2011, Microsoft porzucił jednak Dryad i skupił się głównie na rozwoju projektu Hadoop.
Około roku później pomysł Microsoftu został odświeżony i wykorzystany jako część projektu Tez. Dzięki niemu – zgodnie z testami Yahoo! – wykonywanie skryptów Hive może być nawet kilkanaście razy szybsze.
W międzyczasie w roku 2010 na Uniwersytecie w Berkeley powstał projekt Spark. W artykule Spark: Cluster Computing with Working Sets wprowadzone zostaje pojęcie Resilient Distributed Datasets (RDD), które oznacza kolekcje danych istniejące w środowisku rozproszonym. Na RDD można przeprowadzać operacje MapReduce w Hadoop, a dodatkowo zastosowane są pewne optymalizacje, inspirowane systemem Dryad Microsoftu.

Podobnie jak Dryad, a potem także Tez, Spark nie zapisuje wyników pośrednich operacji w systemie plików. Dodatkowo, spark wspiera tzw. leniwą ewaluację procesów przetwarzania danych. Poszczególne operacje wykonywane są na żądanie – dopiero wtedy, kiedy konieczne jest zwrócenie konkretnych wartości.
Na stronie projektu Spark można znaleźć informację, że niektóre operacje – zwłaszcza operacje wymagające wielu zadań MapReduce – w Sparku można wykonywać nawet sto razy szybciej niż w klasycznym podejściu.
Rekomendacje
Ten post powstał zainspirowany pytaniem, które znalazłem na portalu Quora: Kiedy należy korzystać z Apache Tez, a kiedy z Apache Spark?
W najlepszej z odpowiedzi Sandy Ryza z Cloudery (drugiego obok Hortonworks lidera rozwiązań big data) stwierdził, że Spark jest bardziej dojrzałą wersją Tez, a w dodatku ma wiele innych funkcjonalności, których w Tez brakuje.
Nie da się ukryć, że Tez jest innego rodzaju rozwiązaniem niż Spark. Idea Hortonworks, zgodnie z którą Tez wykorzystywany jest jako pewien silnik optymalizacji wywoływania zadań MapReduce dla skryptów Pig i Hive, wydaje się słuszna. Z pewnością wielu analityków przyzwyczaiło się już do Pig i Hive, dostępnych standardowo w platformach Hortonworks i Cloudera, z pewnością też wiele organizacji wykorzystuje te narzędzia od dawna (z Yahoo! na czele). W tym kontekście Tez to wspaniałe narzędzie, pozwalające zwiększyć wydajność istniejących procesów.
Tez ciągle jest jednak narzędziem niedojrzałym i – wydaje się – niskopoziomowym. Brak w nim spójnego i przyjaznego dla analityka/programisty API, które z czasem powstało w projekcie Spark, w miarę jego rozwoju. Mimo że oba projekty mają wspólne źródła, to właśne Spark jest narzędziem dojrzalszym.
Tak jak napisał Sandy Ryza, używaj Tez jako silnika optymalizującego wywołanie skryptów Hive i Pig, ale jeśli chcesz definiować procesy przetwarzania danych z wykorzystaniem MapReduce, to Spark będzie dużo lepszym wyborem.
Klasyczny w big data przykład zliczania słów w dokumencie zajmuje w Tez ponad 200 linijek. Przykład zliczania słów w Spark w Javie 8 jest tak krótki, że pokazuję go poniżej (a w Scali, albo w Pythonie byłby jeszcze krótszy i bardziej przejrzysty):
package io.github.dzikowski.apps;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class SparkWordcount {
public static void main(String... args) {
// run spark
SparkConf conf = new SparkConf().setAppName("WordCount").setMaster("local[*]");
JavaSparkContext spark = new JavaSparkContext(conf);
// count words
JavaPairRDD<String, Integer> counts = spark.textFile("hdfs://...")
.flatMap(line -> Arrays.asList(line.split(" ")))
.mapToPair(word -> new Tuple2<String, Integer>(word, 1))
.reduceByKey((a, b) -> a + b);
// save results
counts.saveAsTextFile("hdfs://...");
}
}Warto zajrzeć
- Dokumentacja Hortonworks: ogólnie o plaftormie, gdzie są też opisane główne komponenty środowiska Hadoop, ogólnie o Tez, ogólnie o Oozie, ogólnie o Spark.
- Wielka tabelka, w której są krótko opisywane różne projekty powiązane z big data. Tabelka jest aktualizowana na bieżąco – to dobre źródło, żeby nadążyć z aktualizacją własnej wiedzy w tak dynamicznie zmieniającej się dziedzinie.
- Krótka odpowiedź na pytanie, kiedy używać Spark, a kiedy Tez, która w znacznej mierze była inspiracją do powstania mojego wpisu.
- Artykuł Microsoftu z 2007 roku, opisujący szkielet rozwiązania, które kilka lat później zostało wprowadzone w Tez.
- Artykuł Uniwersytetu Berkeley z 2010 roku, opisujący szkielet rozwiązania, które wykorzystywane jest w Spark.
Postscriptum (2015-01-14)
Zależności pomiędzy Tez a Spark są jeszcze bardziej zagmatwane. Silnikiem wykonywania skryptów Hive i Pig może być nie tylko MapReduce i Tez, ale także Spark (dla Hive, dla Pig). Dodatkowo Hortonworks przygotowało ulepszoną wersję Spark, która w testowanych przypadkach spisuje się lepiej, bo… sam Spark nie jest wykonywany bezpośrednio w YARN, tylko najpierw optymalizowany przez Tez. Czyli Tez staje się silnikiem optymalizacji dla Spark.
W tym świetle nie wydaje się wykluczone, że niedługo wykonywanie skryptów Hive, czy Pig będzie optymalizowane przez Spark optymalizowany przez Tez. Widać też wyraźniej zależności pomiędzy tymi projektami: Tez jest narzędziem niższego poziomu, a Spark narzędziem bardziej ogólnym.