Spark w technologiach big data
28 Jan 2015Spark wydaje mi się najbardziej wszechstronnym i w większości przypadków najlepszym narzędziem do analizy dużych zbiorów danych. Jak to często bywa, zanim Spark powstał i stał się fajny, największe firmy zaczęły już korzystać z innych narzędzi. Tym razem jednak dzieje się coś dziwnego: zamiast ściśle trzymać się tego, co już dobrze znane, nawet te firmy w coraz większym stopniu korzystają ze Spark i znajdują dla niego nowe zastosowania.
Moim zdaniem można rozróżnić trzy główne podejścia do przetwarzania big data:
- Przetwarzania dużych zbiorów statycznych danych (tzw. batch processing), w tym operacje Extract, Transform, Load (ETL) oraz analizy na żądanie (ad hoc analysis).
- Przetwarzanie strumieni danych (stream processing).
- Przetwarzanie dużych zbiorów danych w pamięci operacyjnej (in-memory computing).
W którym z tych obszarów mieści się Apache Spark? Uwaga: we wszystkich.
Ogólnie o Spark
Celem Spark jest udostępnienie łatwego i uniwersalnego sposobu przetwarzania dużych, rozproszonych zbiorów danych. Tradycyjne podejście – MapReduce – skaluje się bardzo dobrze, ale ma stosunkowo skomplikowane API, przez co tworzenie takich programów jest bardzo pracochłonne. Spark rozdziela przetwarzanie danych na poszczególne zadania MapReduce, ale dzieje się to w tle. Dzięki eleganckiemu i intuicyjnemu API, przetwarzanie big data jest dużo łatwiejsze.
Centralną koncepcją Apache Spark są tzw. resilient distributed datasets, co można przetłumaczyć jako odporne na awarie, rozproszone kolekcje danych. Istnieją one na wielu maszynach jednocześnie (na dyskach lub w pamięci operacyjnej), a w przypadku awarii są odtwarzane.
Na tych kolekcjach danych można przeprowadzać określone operacje, czyli – zgodnie ze słownikiem Spark – transformacje i akcje:
- Transformacje (ang. transformations) polegają na przekształceniach obiektów (czyli operacje Map), filtrowaniu listy obiektów, albo grupowaniu. Transformacje są wykonywane dopiero wtedy, kiedy pojawi się akcja, która wymaga dostępu do przetworzonych danych (leniwa ewaluacja).
- Akcje (actions) polegają np. na zliczaniu (czyli też z wszystkuim, co związane z operacją Reduce), zapisywaniu, albo wyświetlaniu przetworzonych danych.
Praca ze Spark polega po prostu na opisywaniu w zwięzły sposób operacji przetwarzania rozproszonych kolekcji danych. Konieczne jest dostosowanie się do kilku reguł, ale elegancka składnia Spark i silna orientacja na dane pozwalają tworzyć programy znacznie bardziej czytelne niż skrypty Hive, czy Pig.
Oprócz tego, Spark jest narzędziem uniwersalnym. W łatwy sposób pozwala łączyć różnego typu operacje na danych: skrypty SQL, operacje ETL, uczenie maszynowe, obliczenia na grafach, czy przetwarzanie tekstu.
Wreszcie, należy wspomnieć o bardzo wyskiej wydajności. W listopadzie 2014 roku Spark pobił rekord wydajności sortowania 100 petabajtów danych (1 PB = 1 000 000 TB), wykonując tę czynność w 23 minuty na – ponad 3 razy szybciej niż Hadoop MapReduce (i to bez wykorzystywania wszystkich możliwości optymalizacji wydajności Spark).
Na tak wysoką wydajność Spark wpływają przede wszystkim dwa czynniki. Po pierwsze, leniwe wykonywanie transformacji i optymalizacja sekwencji tranformacji, dzięki czemu minimalizowana jest ilość koniecznych do wykonania operacji na danych, oraz operacji odczytu i zapisu na dysku. Po drugie, możliwość tymczasowego zapisywania rezultatów w pamięci podręcznej (ang. cache), co także prowadzi do zminimalizowania odczytu i zapisu danych na dysku. Dzięki temu w Spark można nawet wykonywać iteracyjne algorytmy uczenia maszynowego, co bez takich optymalizacji – w klasycznym MapReduce, Hive, czy Pig – byłoby nie do pomyślenia.
Oczywiście Spark ma niewielkie wady. Zanim jednak do nich przejdę, zacznę od porównania Spark z innymi uznanymi narzędziami big data.
Spark vs Pig
Jednym z popularniejszych rozwiązań do przetwarzania big data wydaje się być Apache Pig, które umożliwia tworzenie skryptów w specjalnym języku, Pig Latin, i wykonywanie ich w środowisku rozproszonym. Pig zostało stworzone około 2006 roku przez Yahoo!, a w roku 2007 stało się projektem Open Source pod skrzydłami Apache Foundation.
Pig dobrze nadaje się do przetwarzania danych, jednak mimo tego, że ma już swoje lata, ciągle jest narzędziem stosunkowo wolnym. Dopiero od niedawna Hortonworks dostarcza Pig zintegrowane z Tez, a Sigmoid Analitics, zamiast Tez jako silnika optymalizacji dla Pig, wykorzystuje… Spark.
Oprócz kilku istotnych zalet (odporność na błędy i obsługa wielu formatów danych, dobre wsparcie, integraja z platformami Hortonworks i Cloudera), Pig ma jednak jedną wadę, która przyćmiewa wszystko inne: skrypty w Pig są niesamowicie brzydkie. Nie jest tu oczywiście problemem moje poczucie estetyki, ale ich nieczytelność.
Poniżej zamieszczam przyklad zliczania słów, napisany w Pig Latin (z Wikipedii).
input_lines = LOAD '/tmp/my-copy-of-all-pages-on-internet' AS (line:chararray);
-- Extract words from each line and put them into a pig bag
-- datatype, then flatten the bag to get one word on each row
words = FOREACH input_lines GENERATE FLATTEN(TOKENIZE(line)) AS word;
-- filter out any words that are just white spaces
filtered_words = FILTER words BY word MATCHES '\\w+';
-- create a group for each word
word_groups = GROUP filtered_words BY word;
-- count the entries in each group
word_count = FOREACH word_groups GENERATE COUNT(filtered_words) AS count, group AS word;
-- order the records by count
ordered_word_count = ORDER word_count BY count DESC;
STORE ordered_word_count INTO '/tmp/number-of-words-on-internet';Programowanie jest sposobem komunikowania się. Jeśli nowa osoba, znająca Pig i Spark, otrzymałaby do analizy po jednym skrypcie z każdego z tych dwóch narzędzi, a skrypty robiłyby dokładnie to samo, to zapoznanie się z wersją w Spark, zajęłoby zdecydowanie mniej czasu.
Język Pig Latin pełen jest sprzeczności i niekonsekwencji.
Niektóre elementy muszą być pisane zawsze wielkimi literami (np. funkcja SUM), niektóre mogą być pisane albo małymi, albo wielkimi (np słowa kluczowe LOAD, albo GENERATE).
Sam język jest imperatywny, ale miejscami widać mocną inspirację deklaratywnym SQL.
Pewnym problemem może być także brak kontroli typów i trochę bardziej zaawansowanych konstrukcji języka, np. tradycyjnie rozumianej instrukcji warunkowej, albo struktur danych.
Wszystko to sprawia, że utrzymanie i rozbudowa skryptów Pig – mimo że łatwiejsze, niż skryptów Hive – nie jest wcale proste.
Spark vs Scalding
Inne podejście do przetwarzania statycznych danych w środowisku rozproszonym reprezentuje Cascading. Powstaniu Cascading przyświecał podobny cel, jak Spark i Pig – umożliwienie przetwarzania big data, ukrywając jednocześnie złożoność MapReduce. Projekt został wykorzystany przez Twittera, który stworzył do Cascading zgrabne API w Scali i w 2012 roku je upublicznił. Tak powstał projekt Scalding.
Cascading i Scalding są łatwiejsze w użyciu niż MapReduce (Scalding nawet o wiele łatwiejszy), a przy tym dają możliwości, których w Pig nie ma: możliwość wykorzystania bogactwa struktur popularnego języka programowania (a nie hermetycznego, dedykowanego, jak Pig Latin), możliwość kontroli typów, czy – co chyba najważniejsze – pisania testów jednostkowych.
Trzeba przyznać, że przykład zliczania słów w Scalding (z oficjalnej dokumentacji projektu), wygląda dużo lepiej niż w Pig:
class WordCountJob(args : Args) extends Job(args) {
TypedPipe.from(TextLine("/path/to/input-file"))
.flatMap(line => line.split("""\s+"""))
.groupBy(word => word)
.size
.write(TypedTsv("/path/to/output-file"))
}Albo przykład uproszczony:
class WordCountJob(args : Args) extends Job(args) {
TypedPipe.from(TextLine("/path/to/input-file")))
.flatMap(_.split("\\s+"))
.group
.sum
.write(TypedTsv("/path/to/output-file"))
}Dla porównania przykład w Spark, który zadziała niemal identycznie:
val spark = new SparkContext(new SparkConf().setAppName("WordCount"))
spark.textFile("/path/to/input-file")
.flatMap(line => line.split("""\s+"""))
.map(word => (word, 1))
.reduceByKey(_ + _)
.saveAsTextFile("/path/to/output-file")Zliczanie słów w Scalding i Spark wyglądają bardzo podobnie. Jedną z przyczyn takiego stanu rzeczy jest po prostu to, że w obu przypadkach wykorzystywany jest potencjał języka programowania Scala, w który operacje Map i Reduce są w zasadzie wbudowane.
Tym, czego może nie widać jeszcze na powyższych przykładach (ale co dobrze widać tutaj), jest nieco inna filozofia obu projektów. Spark jest narzędziem bardzo ogólnym, natomiast Scalding wydaje się bardziej przystosowany do operacji na danych tabelarycznych. To często powoduje, że kod w Scalding jest znacznie krótszy niż w Spark w przypadku manipulacji wieloma kolumnami danych, czy też przy wczytywaniu i zapisywaniu plików CSV/TSV. W takich zastosowaniach Scalding wydawałby się lepszy… gdyby nie kwestia wydajności. Ostatnio nawet Twitter upublicznił prezentację, pokazującą większą wydajność Spark.
Poza tym Scalding nie nadaje się do przetwarzania strumieni danych i brakuje w nim interaktywnej konsoli.
Spark vs Hive
Hive zostało stworzone przez Facebooka, ale aktywnie wspierają je też takie firmy, jak Amazon i Netflix. Hive pozwala na wykonywanie zapytań na danych w języku Hive QL, który jest bardzo podobny do SQL. Co się z tym wiąże, ma wszystkie wady i zalety języka SQL.
Najlepiej się nadaje do analizy statycznych danych tabelarycznych, a nawet – w przypadku zastosowania własnych formatów interpretacji danych, tzw. SerDe – analizy plików, tak jakby były tabelami. W Hive można zdefiniować takie SerDe, że nawet nie pliki TSV, ale katalogi z plikami XML lub JSON, mogą być traktowane jako tabele danych i odpytywane w Hive jako tabele.
Inną znaczącą zaletą, której też nie ma Spark, jest optymalizacja przechowywania tabel, pozwalająca na szybszą pracę z danymi (por. PARTITIONED BY i SKEWED BY z oficjalnej dokumentacji), albo próbkowanie i rodzielanie danych do tzw. buckets, co jest bardzo przydatne w efektywnej analizie big data.
Zaletą jest także w zasadzie brak konieczności uczenia się nowego języka w przypadku analityków danych, znających SQL. Osoby pracujące do tej pory na standardowych hurtowniach danych łatwo powinny się przestawić na Hive.
W tym momencie znów należy wskazać uniwersalność Spark, jednakże tutaj może ona być traktowana jako wada. Hive za to nie nadaje się do przeprowadzania skomplikowanych analiz na danych (np. wymagających analizy trendów, albo uczenia maszynowego); nie nadaje się także do operacji ETL. Jest po prostu narzędziem bardzo wyspecjalizowanym i do tego, do czego zostało stworzone, nadaje się świetnie.
Przykład zliczania słów w Hive (ze StackOverflow):
SELECT word, COUNT(*)
FROM input LATERAL VIEW explode(split(text, ' ')) lTable AS word
GROUP BY word;Potencjał Hive oczywiście został odkryty przez społeczność Apache Spark. Kiedy powstał Spark, Hive było jedynym (i mało wydajnym) narzedziem, które umożliwiało wywoływanie zapytań (podobnych do) SQL w środowisku rozproszonym. Potem społeczność Spark stworzyła projekt Shark, który rónież umożliwiał wywoływanie zapytań SQL, ale dzięki temu, że Shark działał na Spark, a nie na MapReduce, jak Hive, był od niego dużo bardziej wydajny. Shark jednak odziedziczył mnóstwo trudnego w utrzymaniu kodu zaczerpniętego z Hive, co ostatecznie doprowadziło do sytuacji, w której Shark przestał być rozwijany, na rzecz podprojektu Spark: Spark SQL. Spark SQL jest uznawany za wydajniejszy niż Shark (zgodnie z tym artykułem) i w większości jest kompatybilny z Hive (zgodnie z tym artykułem).
Natomiast aby zwiększyć wydajność samego Hive, w tej chwili działają dwie główne inicjatywy. Pierwszą forsuje Hortonworks: silnikiem wykonywania skryptów Hive ma już nie być MapReduce, ale Tez. Druga wyszła ze społeczności Hive i jest wspierana przez Clouderę: silnikiem wykonywania skryptów Hive ma być… Spark.
Spark vs Tez
Relacja pomiedzy Spark i Tez na pierwszy rzut oka wydaje się odległa, jednak przy bliższym spojrzeniu okazuje się, że mają wiele wspólnego. Mają przede wszystkim takie same korzenie i podobną filozofię działania. Mimo że powstały w innych celach, to zarówno Spark i Tez znajdują zastosowanie jako silniki wykonywania skryptów Pig i Hive.
Pisałem już o obu narzedziach w tym poście.
Spark vs Storm
Spark Streaming i Storm służą do podobnych zadań, choć ujmują problem przetwarzania strumieni danych w całkiem inny sposób. Spark został stworzony jako ogólne narzędzie do przetwarzania danych w środowisku rozproszonym, początkowo były to dane statyczne. Z czasem powstał Spark Streaming, rozwiązanie, które wykonywało tzw. micro-batching: transformacje i akcje Spark przeprowadzane były co kilka sekund na nowo pojawiających się danych.
Storm powstał w firmie BackType, która została przejęta przez Twitter, który z kolei w 2011 roku wypuścił Storm jako projekt Open Source. W tej chwili jest wykorzystywany w takich firmach, jak Twitter, Yahoo!, czy Spotify.
Idea, która stoi za Storm jest nieco inna niż ta, która stoi za Spark. Storm powstał od razu jako narzędzie wyspecjalizowane w przetwarzaniu strumieni danych. Stąd też specyficzna terminologia i architektura odbiegająca od podejścia MapReduce.
Podstawowe pojęcia to topologia (ang. topology), spout i bolt. Przetłumaczenie dwóch ostatnich na język polski nastręcza sporo trudności (1 i 2).
Topologia to graf skierowany, w którym krawędzie określają przepływ danych, a wierzchołki to spouts i bolts. Spout to źródło danych, bolt to miejsce, w którym dane są przetwarzane. Przetwarzane i przesłane dane mają postać strumieni krotek (ang tuples).
Topologia może mieć taką postać (źródło):
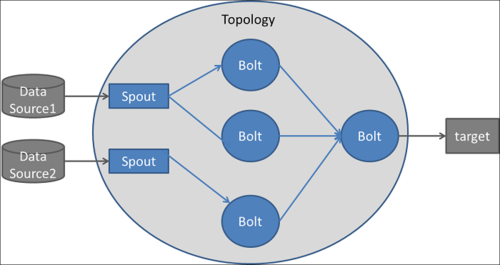
Storm przetwarza dane od razu, krotka po krotce, dopiero rozwinięcie Storm – Storm Trident, przeprowadza micro-batching, który jest czymś podobnym do tego ze Spark Streaming (i przy okazji daje też lepsze gwarancje dostarczania danych, ale o tym będzie we wpisie dedykowanym Storm). Jednak ten model przetwarzania jest całkiem inny, niż w klasycznym Storm.
Przede wszystkim podejście w klasycznym Storm daje gwarancję dostarczenia komukatu (krotki) przynajmniej raz do danego bolt, co oznacza, że może dojść do tego, że jakiś komunikat trafi do danego bolt dwukrotnie. Spark Streaming natomiast gwarantuje przetworzenie danych dokładnie jeden raz (choć podobno istnieją takie scenariusze awarii klastra, które podważają taką gwarancję).
Trudno powiedzieć, czy działa to na korzyść Spark, czy też mamy remis. Zdecydowanie na korzyść Storm przemawia jednak kolejny punkt: (latencja, ang. latency).
Latencja, czy też opóźnienie, to ważny aspekt w przetwarzaniu strumieni danych, gdzie najlepiej, by wszystko działo się jednocześnie. Tymczasem podejście zastosowane w Spark Streaming, micro-batching, wymusza większe opóźnienie, niż topologie Storm. W Storm znacznie łatwiej dość do przetwarzania nowych komunkatów w strumieniu danych w czasie mniejszym niż sekunda, podczas gdy w Spark Streaming standardem jest kilka sekund.
Zderzenie Spark i Storm, to zderzenie uniwersalności ze specjalizacją. Spark może ma większe wsparcie i jest powszechniej wykorzystywany, jednak dla niektórych rozwiązań znacznie lepiej nadają się dedykowane rozwiązania, takie jak Apache Storm.
Spark vs Summingbird
Często wskazywaną zaletą Spark jest to, że używa się takiej samej logiki do przetwarzania danych statycznych i do przetwarzania strumieni danych. Dzięki temu nie trzeba duplikować kodu. Jeśli logika przetwarzania danych zostanie prawidłowo odseparowana, ten sam kod może być wykorzystany w jednym i drugim przypadku.
Rozwijający własne narzędzia big data Twitter doszedł do podobnego wniosku. W Twiterze wykorzystywane są Scalding i Storm, które narzucają konieczność programowania w całkiem innych podejściach. Dlatego powstał Summingbird.
Summingbird pozwala na opisywanie przetwarzania danych w ramach standardowych konstrukcji języka Scala, dorzuca tylko kilka własnych instrukcji. Ale dzięki temu, że przetwarzanie danych zostało zdefiniowane z wykorzystaniem Summingbird, można ten sam kod wykonać w różnych trybach:
- Jako batch processing, gdzie napisany program będzie wywołany na Scalding.
- Jako stream processing, gdzie ten sam program będzie wywołany jako topologia Storm.
- W trybie hybrydowym, jednocześnie na Scalding i Storm, co pozwala na efektywne przetwarzania dużych, ciągle zmieniających się zbiorów danych (i to jest nisza, której Spark wydaje się nie wypełniać).
Tym samym Summingbird, podobnie jak Spark, dostarcza uniwersalny model programowania, jednak korzysta np. ze Scalding, który jest mniej wydajny. Stąd też plany i pierwsze przymiarki Twittera, żeby umożliwić wykonywanie programów Summingbird nie tylko na Scalding, ale też na Spark. Jak to zadziała w praktyce? Zobaczymy.
Czy Spark ma wady?
Oczywiście, ale takie mało znaczące, że muszę wymyślać je niemal na siłę. (Albo jestem takim zaślepionym zwolennikiem Apache Spark, że nie widzę ich wyraźnie).
Rozwiązania, które są na rynku już stosunkowo długo (jak na big data), czyli Pig i Hive doczekały się narzędzi, ułatwiających pisanie i wywoływanie skryptów. Można to robić bezpośrednio w aplikacji Hue, będącej interfejsem WWW do klastra Hadoop, znajdującej się w dwóch najpopularniejszych platformach – Cloudera i Hortonworks. Tym samym, aby wykonywać obliczenia w środowisku rozproszonym w Hive i Pig, nie jest konieczna instalacja żadnego dodatkowego oprogramowania, wystarczy przeglądarka internetowa i dostęp do Hue. Spark jeszcze nie doczekał się takiego interfejsu, co sprawia, że ciągle nadaje się bardziej dla programisty niż analityka.
Pewną wadą Spark może być też technologia, w której został stworzony. Nie da się ukryć, że dopiero w Javie 8 Spark jest porównywalnie zwięzły, jak Spark w Scali i Pythonie. W starszych wersjach Javy trzeba tworzyć specjalne obiekty i klasy na funkcje, co powoduje, że proste przekształcenie z jednej linijki może rozrosnąć się do kilkunastu (i wynika to wyłącznie z braku wsparcia Javy dla wyrażeń Lambda).
Python nie ma pełnego wsparcia w Spark (do niedawna jeszcze nie można było korzystać ze Spark Streaming w Pythonie), a Scala, mimo nadzwyczajnej ekspresyjności i zgodności z JVM, ciągle jest mało popularna. Innymi słowy, kolejną przeszkodą, może być bariera językowa.
Wreszcie drobną wadą Spark może być jego ogólność. Takie narzędzia jak Hive, czy Storm, właśnie dzięki temu, że są wyspecjalizowane, do części zadań nadają się lepiej niż Spark.
Przyszłość
… zdecydowanie należy do Apache Spark, choć trudno powiedzieć, jaka. W zasadzie teraźniejszość też już jest nim silnie naznaczona. Nie przewiduję, że wyparte zostanią takie wyspecjalizowane i świetnie się sprawdzające rozwiązania, jak Hive, Storm, czy Scalding. Pewnie nawet siermiężne Pig tak szybko nie upadnie, bo wiele skryptów Pig działa od dawna i nie ma większego powodu, żeby się ich pozbywać. Pewnie analitycy w dalszym ciągu nie będą (bezpośrednio) korzystać ze Spark, który wśród programistów już teraz ma duże uznanie. Kilka lat młodszy od znanych narzędzi, bardzo szybko znalazł sobie znaczące miejsce w środowisku big data i powinien je w dalszym ciągu umacniać.
Jako pewne ryzyko można rozpatrywać jedną z największych zalet Spark – jego uniwersalność. Może się oczywiście zdarzyć, że powstanie mnóstwo wyspecjalizowanych rozwiązań i każde z nich zabierze Spark część rynku, jednak wydaje mi się to mało prawdopodobne. Historia pokazała, że jeśli jakies rozwiązanie jest wydajne i uniwersalne, szybko zyskuje użytkowników, a główną barierą jest najwyżej zjawisko zwane vendor lock-in. To samo zjawisko, przez które rynek jeszcze nie porzucił Pig i wielu innych narzędzi.
Jednak i tutaj wydaje się, że Spark znajduje sobie niszę. Skoro wykorzystywane są już rozwiązania bazujące na Hive, Pig, czy Summingbird, i te rozwiązania działają wolno, wydajny Spark służy jako silnik, na którym mogą być uruchamiane te narzędzia. Wtedy bezpośrednim konkurentem staje się Tez, który ma tę wadę, że… jest mniej uniwersalny.
Do poczytania
Dzisiejsza sekcja “Do poczytania” jest dużo bardziej obszerna niż zawsze, ponieważ pojawiły się informacje o wielu nowych narzędziach. Wpis był eklektyczny, dotyczył wielu różnych narzędzi, dlatego poniżej prezentuję odnośniki, z których korzystałem i które mogą Ci pozwolić poszerzyć wiedzę z zakresu narzędzi big data.
Apache Spark
- Artykuł opisujący motywację twórców Apache Spark.
- Główna strona projektu Apache Spark. Zawiera między innymi użyteczne przykłady w Scali, Pythonie i Javie.
- Wprowadzenie do Spark – wersja robocza pierwszego rozdziału książki “Learning Spark” wydawnictwa O’Reilly.
- Wpis na StackOverflow o tym, w jaki sposób Spark radzi sobie z obsługą awarii.
- Obszerne zasoby szkoleniowe na stronie Databricks, dostarczającej platformę big data, opierającą się głównie na Spark. Na tej stronie można znaleźć odnośniki do wielu prezentacji z warszatatów ze Spark, a także odnośniki do darmowych kursów online ze Spark.
- Inny punkt widzenia: prezentacja Twittera (wykorzystującego Pig oraz Summingbird + Scalding + Storm) o tym, jakie może mieć zalety przejście na Spark. Prezentacja zawiera także porównanie wydajności Spark z Pig i Scalding.
Pig
- Główna strona projektu Apache Pig.
- Przewodnik z przykładami.
- Przystępny opis zalet i wad Pig.
- Książka “Programming Pig” dostępna za darmo, napisana przez Alana Gatesa z Yahoo!.
Scalding
- Główna strona projektu Twitter Scalding.
- Porównanie wydajności Spark vs Scalding (z lipca 2014).
- Porównanie przykładów kodu Scalding i Spark.
Hive
- Główna strona projektu Apache Hive.
- Artykuł Cloudery o Hive na Spark, instrukcja uruchamiania Hive na Spark.
- Informacje projekcie Spark SQL i jego relacji do Shark.
Storm
- Główna strona projektu Apache Storm, w tym omówienie najważniejszych pojęć i architektury.
- Wpis o Storm na bloku Twittera.
- Wytłumaczenie tego, w jaki sposób działa przetwarzanie rozproszone w Storm.
- Porównanie 1, porównanie 2 i porównanie 3 Apache Spark z Apache Storm.
Summingbird
- Główna strona projektu Twitter Summingbird.
- Jak powstał i do czego służy Summingbird – wpis na blogu Twittera.
- Artykuł opisujący kompleksowo, jak działa Summingbird i jakie są jego powiązania ze Scalding i Storm.
Dodatkowo polecam też stosunkowo stare, ale i tak zawierające sporo ciekawych informacji porównanie Pig, Scalding, Hive, Spark i innych narzędzi.