Continuous Deployment w GitLabie
28 Nov 2015Jak pewnie połowa programistów, prowadzę swoje małe projekciki, które być może kiedyś podbiją świat. Postanowiłem skonfigurować dla nich proces Continuous Deployment z wykorzystaniem GitLaba. W tym poście napisałem trochę o Continuous Integration, Delivery i Deployment, a potem pokazałem, w jaki sposób zrobiłem to dla jednego z moich projektów.
Do tej pory korzystałem z BitBucket, którego główną korzyścią (dla mnie) były darmowe prywatne repozytoria (na Githubie taka przyjemność kosztuje 7 dolarów miesięcznie). Jeśli chodzi o hosting i wdrażanie, to korzystałem z różnych rozwiązań. Kiedyś z Heroku (świetne na demo, drogie dla wersji produkcyjnych), potem z Dokku na własnym serwerze od Digitalocean (w rozsądnej wersji 10 dolarów miesięcznie). Jedną aplikację mam na Google App Engine, a inną wrzucam bezpośrednio na VPS (przez SCP).
Dla Heroku i Dokku Continuous Deployment jest proste. Po prostu wrzucam zmiany do repozytorium do master branch i na serwerze wywoływane jest budowanie aplikacji, a zbudowana aplikacja staje się wersją produkcyjną. W Google App Engine to kwestia wywołania dodatkowego polecenia, które wrzuca nową wersję aplikacji na serwer. Wrzucanie przez SCP jest podobnie pracochłonne, a pewnie przeczy większości dobrych praktyk.
W zasadzie Heroku i Dokku dają to, co chciałem osiągnąć. Wystarczy zrobić push do repozytorium, a na serwerze buduje się nowa wersja aplikacji. Gdybym skonfigurował Dokku z Apache2, też pewnie byłoby dobrze, jednak mam wrażenie, że nie miałbym nad całym procesem wystarczającej kontroli. Poza tym Dokku ciągle jeszcze nie wydaje się rozwiązaniem dojrzałym – miałem sporo problemów z konfiguracją wtyczek, a część rzeczy się sypała (możesz też zajrzeć na tę dyskusję na Hacker News). Słowem – nie chciałem Dokku. A Heroku, jak już wspomniałem jest drogie.
Z kolei w firmie, dla której obecnie pracuję, korzystam z Jenkinsa, co jest świetnym rozwiązaniem, bo w Jenkinsie można zrobić wszystko. Na wszystko są też wtyczki, podobnie dojrzałe i sprawdzone jak sam Jenkins. Ale Jenkins ma wielką wadę. Dość dużo czasu trzeba poświęcić na to, żeby go skonfigurować, a także zintegrować z innymi aplikacjiami (np. z repozytorium kodu). Poza tym wygląd Jenkinsa i UX już dość mocno odstają od bieżących standardów.
W związku z tym wszystkim postanowiłem wypróbować coś nowego, GitLab, który out of the box może dać mi wersjonowanie na Gicie, wbudowany mechanizm CI, issue tracker, code reviews i inne ciekawe rzeczy.
Continuous Integration, Delivery i Deployment
Ale zacznijmy od początku. Pewnie kojarzysz te trzy pojęcia: Continuous Integration, Continuous Delivery i Continuous Deployment. Każde z nich znaczy coś trochę innego, ale wszystkie związane są z tym, że proces budowania systemu wywoływany jest automatycznie i często.
{kind=link}
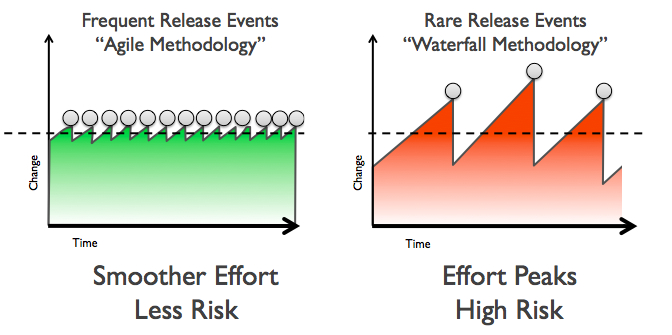
Jeśli często wrzucasz zmiany na produkcję, to na pewno te zmiany są mniejsze, niż gdybyś wrzucał je rzadko. Tym samym trudniej jest coś zepsuć i mniejsze ryzyko, że coś pójdzie nie tak.
Bardzo ważna jest też, jak wspominał niedawno na jednym ze spotkań Jarosław Pałka, możliwość odwrócenia zmian. Jeśli się okaże, że nowa wersja aplikacji nie działa tak, jak powinna, trzeba cofnąć te zmiany. I tutaj znów korzystniejsze jest częstsze wypuszczanie wersji, bo łatwiej jest odwrócić mniejsze zmiany niż większe. A jeśli jeszcze wdrożenie systemu wymaga jakiejś dodatkowej konfiguracji, ustawiania zmiennych środowiskowych, plików konfiguracyjnych, czyli tego, na co wszystkie Continuous (…) patrzą bardzo niechętnie, to życzę szczęścia w odwracaniu dużych zmian – na pewno będzie potrzebne.
Tak jak wspominałem, mamy trzy podstawowe pojęcia: Continuous Integration, Continuous Delivery i Continuous Deployment. Pierwsze z nich oznacza częste włączanie zmian kodu źródłowego do głównego repozytorium, a najczęściej także automatyczne uruchamianie testów w jakimś zewnętrznym środowisku, np. na Jenkinsie. Dzięki temu można uniknąć sytuacji, kiedy okazuje się, że po miesiącu pracy wrzucamy do repozytorium kod, a po kolejnym miesiącu, kiedy chcemy uruchomić aplikację, okazuje się że ten kod nie współpracuje dobrze z innymi komponentami systemu i spędzamy tydzień, żeby ten problem naprawić. Ciągle integrujemy, czyli na bieżąco – i automatycznie – sprawdzane jest, czy nasze zmiany dobrze współdziałają z całością systemu.
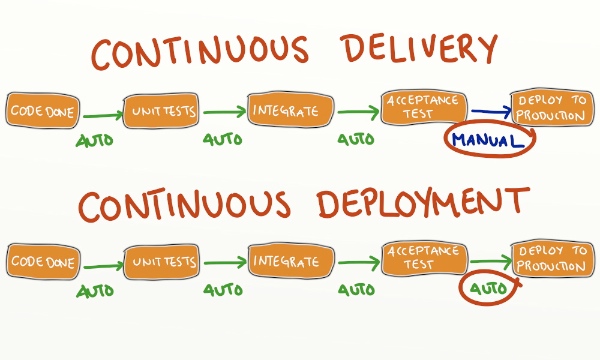
Kolejne dwa pojęcia: Continuous Delivery i Continuous Deployment bywają często mylone. Różnicę pomiędzy nimi dobrze pokazuje ten obrazek (źródło):
{kind=link}
Czyli podstawową różnicą jest to, czy na produkcyjną wersję aplikacji zmiany wrzucane są automatycznie, czy też manualnie. W Continuous Delivery mamy do dyspozycji szereg kolejnych wersji, które przeszły testy i są gotowe na wrzucenie na środowisko produkcyjne. Mamy też kogoś, kto w razie potrzeby bierze którąś z tych wersji i wrzuca ją na to środowisko.
W przypadku Continuous Deployment, kiedy w master branch lądują zmiany, automatycznie uruchamiane są testy, aplikacja jest budowana i wrzucana na środowisko produkcyjne. Albo np. to automatyczne wrzucanie na środowisko produkcyjne odbywa się zgodnie z jakimś ustalonym harmonogramem.
Ja na potrzeby mojej aplikacji chciałem skonfigurować właśnie Continuous Deployment, kiedy mój push do master branch powoduje wrzucenie zmian na środowisko produkcyjne.
Zanim jednak przejdę do mojego procesu, chciałbym polecić kilka linków. Po pierwsze, lista dobrych praktyk Continuous Integration z anglojęzycznej Wikipedii. Słowniczek z bloga GitLaba, opisujący różne pojęcia, które w CI/CD są często używane, a także pojęcia, które będą ważne z punktu widzenia pracy z GitLabem. Przyda się, jeśli jeszcze nie pracowałeś z Githubem, Bitbucket, GitLabem, albo inną tego rodzaju platformą. I jeszcze jeden artykuł z bloga GitLaba, o tym, dlaczego powinieneś używać Continuous Integration.
Co chciałem osiągnąć
Aplikacja, dla której chciałem skonfigurować proces Continuous Deployment, to mój życiorys online, który przygotowałem specjalnie na potrzeby rekrutacji. Jest to aplikacja (na razie) bez back-endu, sam interfejs z kilkoma fajerwerkami (AngularJS). Przygotowałem ją zgodnie z dobrymi praktykami – wszystkie zasoby są minifikowane, dzięki NodeJS i nieocenionemu Web Starter Kit.
Zbudowanie takiej aplikacji polega na wywołaniu polecenia gulp, dzięki czemu w folderze dist lądują przygotowane do publikacji zasoby.
Na początku kod źródłowy wersjonowałem na BitBucket, a dystrybucję aplikacji wrzucałem na VPS z Apache2 przez SCP.
Czyli, żeby opublikować zmiany, musiałem wykonać następujące kroki:
- Commit i push kodu źródłowego (konieczne podanie danych autoryzacji do repozytorium).
- Wywołanie budowania dystrybucji aplikacji (
gulp). - Wyczyszczenie na VPS aktualnej wersji aplikacji (konieczność zalogowania na serwer).
- Wrzucenie nowej wersji dystrybucji na serwer (znów konieczne podanie danych logowania do serwera).
W przypadku, gdy jakieś zmiany chciałbym cofnąć, musiałem cofnąć zmiany w repozytorium, a potem znów wykonać kroki od 2-5.
Można się spierać, że część tych czynności można by usprawnić bez wprowadzania Continiuous Deployment, na przykład automatyczne logowanie do serwera (klucz SSH), jednak ja zamiast usprawniać ten proces, postanowiłem wprowadzić nowy, w którym nie musiałbym sam wywoływać budowania dystrybucji aplikacji, ani samodzielnie zamieszczać danych na serwerze. Wszystko miało ograniczyć się tylko do pierwszego kroku.
Moje Continuous Deployment
Ostatecznie moje rozwiązanie wykorzystuje GitLaba i znaleziony na Githubie projekt Git-Auto-Deploy. Mam trzy serwery. Na jednym z nich zainstalowany jest sam GitLab, czyli tam znajduje się repozytorium kodu, a także konfiguracja procesu Continuous Integration w GitLabie (każdy plik z konfiguracją znajduje się w samym projekcie, zgodnie z konwencją GitLaba). Na drugim zainstalowany jest GitLab Runner, który odpowiada za budowanie aplikacji. Trzeci serwer to wreszcie środowisko produkcyjne z Apache2.

-
Cały proces rozpoczyna się w momencie, kiedy w lokalnym repozytorium wywołuję
git pushdo gałęzimasterrepozytorium na serwerze, na którym jest GitLab. -
GitLab w momencie zmiany repozytorium informuje GitLab Runnera, że należy zbudować projekt.
-
GitLab Runner uruchamia przygotowany przeze mnie kontener Dockera z zainstalowanymi NodeJS i Git.
-
W tym kontenerze wywołana jest aktualizacja plików źródłowych (
git pull), następnie samo zbudowanie źródeł i przygotowanie folderu z dystrybucją (wygenerowany przezgulpfolderdist). Potem uruchamiany jest przygotowany przeze mnie skrypt, który klonuje z serwera z GitLabem repozytorium z wersjami produkcyjnymi aplikacji (git clone) i aktualizuje to repozytorium nową dystrybucją. Zmiany są wysyłane na serwer z GitLabem (git push). -
Na projekt, w którym znajduje się zbudowana aplikacja (wersje produkcyjne), założony jest tzw. Git web hook. Kiedy coś w repozytorium zostanie zmienione, wysyłane jest zapytanie HTTP do mojego serwera produkcyjnego.
-
Na serwerze produkcyjnym jest uruchomiony Git-Auto-Deploy, który nasłuchuje Git web hooków na określonym porcie. W momencie, kiedy taki hook do niego dojdzie, wywołuje aktualizację dystrybucji aplikacji (czyli
git pullna repozytorium z wersjami produkcyjnymi). Ponieważ to właśnie aktualizowane pliki są serwowane przez Apache2, zmiany od razu są widoczne na produkcji.
Podczas konfiguracji tego procesu musiałem zadbać o kilka rzeczy, a przede wszystkim o bezpieczeństwo komunikacji. Po pierwsze mogę zmienić kod źródłowy aplikacji i wysłać zmiany do repozytorium . Aby było bezpieczniej, sam proces budowania aplikacji wywoływany jest na innym serwerze niż GitLab. To wszystko jest jak najbardziej OK.
Nieco słabszym rozwiązaniem, z punktu widzenia bezpieczeństwa jest to, że kontener Dockera może zmodyfikować jedno z repozytoriów na GitLabie. Jednak jest do tego przeznaczony specjalny użytkownik, a jego dane autoryzacji są zaszyte w kontenerze Dockera i nie są nigdzie przesyłane (oprócz samej autoryzacji na GitLabie). Poza tym można wymusić konieczność akceptacji zmian przez innego użytkownika (wtedy jednak przechodzimy z Continuous Deployment na Continuous Delivery).
I wreszcie serwer produkcyjny nasłuchuje jedynie zmian konkretnego repozytorium na GitLabie. Nawet jeśli w jakiś sposób Git web hook zostanie sztucznie wywołany, to jedyna rzecz, jaka może się wtedy przydarzyć, to pobranie najnowszej wersji repozytorium.
Is It Worth the Time?
Skonfigurowanie tego wszystkiego, razem z instalacją dwóch serwerów na GitLaba, zajęło mi dwa dni, co wydaje się wcale nie takim dużym nakładem na stworzenie procesu Continuous Deployment, który może nie jest gotowy do zastosowania na większą skalę, ale działa i jest w miarę bezpieczny.
Teraz od momentu wywołania git push origin master na lokalnym komputerze do pojawienia się zmian na produkcji mija 45 sekund.
A ponieważ sam pracuję na pełen etat, muszę dbać o to by rozwijać moje małe projekciki szybko, robić dużo małym nakładem czasu.
Dlatego skonfigurowałem sobie tego rodzaju Continuous Deployment i liczę na to, że się zwróci.
Swoją drogą wydaje mi się, że korzystanie z nowych, a nie ciężkich i sprawdzonych rozwiązań we własnych projektach wynika nie tylko z tego, że chcemy się nauczyć czegoś nowego, ale też z tego, że chcemy coś robić szybko. Ale to już inna historia.